How Do ZFS Snapshots Really Work?
Before discussing how a snapshot works in Open-E JovianDSS, we should start with its definition.…
Read More#1 Software for Data Storage, Backup & Business Continuity

ZFS stands for Zettabyte File System and is a file system originally developed by Sun Microsystems for building next-generation NAS solutions with better security, reliability, and performance. ZFS was designed in 2001 by Matthew Ahrens and Jeff Bonwick and it was supposed to be a next-generation file system for another Sun Microsystems’ system called OpenSolaris. A port for FreeBSD was made in 2008. Unlike other systems on the market, ZFS is a 128-bit file system offering virtually unlimited capacity. In turn, ZFS on Linux (ZOL) was created in 2013. Brian Behlendorf, Jorgen Lundman, Aron Xu, and Richard Yao were among those who helped to create and maintain ZOL.
Learn more about how Open-E JovianDSS utilizes the ZFS features.
After the purchase of Sun Microsystems by Oracle, OpenSolaris was no longer an open-source project. Also, two-thirds of the system developers left Oracle at that time. In September 2013, OpenZFS project was founded by the developers who previously worked on OpenSolaris. They continued to work on an open-source implementation of ZFS.
ZFS is licensed under the Common Development and Distribution License that is incompatible with the GNU General Public License and this is why it cannot be included in the Linux kernel. The reason why the license is kept unchanged is the fact that it is nearly impossible to contact all of the contributors to the OpenZFS implementation.
ZFS comprises functions of a copy-on-write file system, logical volume manager, and software RAID for serving the purposes of highly scalable storage. To understand how ZFS works, you need to get familiarized with the basic concepts displayed in the diagram below.
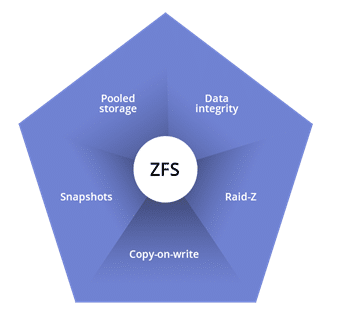
Let us now briefly explain concepts from the diagram.
Pooled storage is basically a ZFS pool that is a collection of one or more vdevs that are virtual devices storing the data. The ZFS pool, also called Zpool, serves as the highest data container in the whole ZFS system. The Zpool is used to create one or more file systems (datasets) or block devices (volumes). These file systems and block devices share the remaining pool’s space. Partitioning and formatting operations will be conducted by the ZFS system.
Copy-on-write can be explained as follows. On most file systems, the data is lost forever once it is overwritten. On ZFS, on the other hand, the new information is written to a different block. The file systems’ metadata is then updated to the point of the new information once the write is complete. This results in preserving the old data in case of a system crash or other harmful event.
The snapshot is a read-only copy of the file system created during a particular point in time. It is possible to make snapshots of entire datasets or pools. The snapshot includes the original system version of the file system together with any changes made once the snapshot has been taken. In simple terms, a differential read-only copy is being created while creating a snapshot. You are able to revert the changes by performing a rollback operation of the snapshot. Bear in mind that you will lose all changes since the snapshot was taken. Read an article about how do snapshots really work>>
Data integrity can be elaborated in the following way. While writing data, a checksum is calculated and written together with it. Later on, when the data is read, the checksum is calculated once more. In case the checksums of the written and read data do not match, a data error is detected. An attempt to correct the error automatically will be then made by the system.
RAID-Z is an implementation of a modified RAID-5. On ZFS, it is capable of overcoming the write hole error detected in original RAID-5. The basic level of RAID-Z, that is, RAID-Z1 requires three disks to work: two disks for storage and one for parity. In turn, RAID-Z2 has to have two disks for storage and two for parity. RAID-Z3 has to have minimum two storage drives and three drives for parity. Note that drives have to be placed in multiples of two when they are added to the RAID-Z pools.
Taking everything into consideration, the ZFS is undoubtedly a file system offering a vast array of possibilities. Not only it is possible to manage data in an efficient and innovative way but also in case of a harmful event, you are able to restore your data without any interruptions to your work. Additionally, in case of a failure, the whole system can be easily restored by using the snapshot capability and reverting the system to a particular point in time.



 New Case Studies on our Website
New Case Studies on our Website Open-E Data Storage Software V7 verified as Citrix Ready
Open-E Data Storage Software V7 verified as Citrix Ready Apple Time Machine and Open-E DSS V6. Short step-by-step and one tip
Apple Time Machine and Open-E DSS V6. Short step-by-step and one tip All hands on deck! Open-E needs your nominations
All hands on deck! Open-E needs your nominations How to Protect Your Data Storage from Hackers
How to Protect Your Data Storage from Hackers Hyper-convergence with Open-E and ONE IN COM
Hyper-convergence with Open-E and ONE IN COM
Leave a Reply